

清华大学与北京邮电大学最新研究成果 从具身竞争与对抗中提升自己:竞争行为学习与对抗形态学习
文章来源 机器人大讲堂
在人工智能和机器人领域,具身交互竞争与对抗正逐渐成为研究的焦点。先前AlphaGo在围棋游戏对抗中的成功无疑是一个人工智能的重要里程碑,而具身交互竞争与对抗将战局延伸至有身体的智能体间的对抗,并强调智能体在交互中学习和进化。
近日,清华大学与北京邮电大学科研团队,围绕竞争性学习框架方向,发表了两项最新的研究进展。研究人员通过理解竞争信息在多智能体竞争中所扮演的角色,通过使用竞争信息激发智能体潜力。除此之外,团队还探索了在交互对抗中如何同步发育智能体的形态,以引导智能体向更强的方向进化。该团队研究成果已分别在ICRA2024与IJCAI2024上发表。
Stimulate the Potential of Robots via Competition:
https://arxiv.org/abs/2403.10487
CompetEvo: Towards Morphological Evolution from Competition:
https://arxiv.org/abs/2405.18300
▍理解竞争信息——通过竞争激发智能体潜力
在竞争激烈的环境下,我们往往会感受到压力,这种压力主要来自于面对竞争对手时取胜的愿望。虽然压力可能会让我们感到焦虑,但它也有可能成为我们挖掘自身潜能、努力追赶并超越他人的动力。受到这一启发,研究人员提出了一个竞争性学习框架。该框架能够帮助单个智能体从竞争中获取知识,充分激发其在竞赛中的动态潜力。为了实现这个功能,研究人员将竞争者之间的竞争信息引入,作为额外的辅助信号,来学习并优化运动策略。

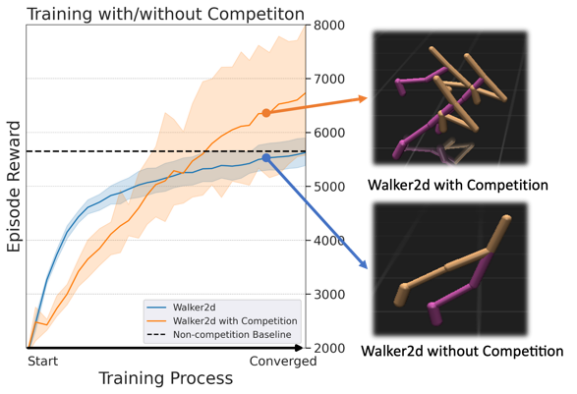
研究人员通过运行一个多智能体竞争任务来获得竞争信息,以便利用竞争信息来区分正数据或负数据。每个智能体的观测信息包括两部分:本体状态信息与竞争性信息。在研究人员设置的多智能体赛跑的任务下,竞争性信息就是多个智能体间的相对速度或相对位置。
竞争性学习框架主要包括两个部分:训练和评估。在训练阶段,智能体的观测信息包括本体信息和竞争性信息,所有的智能体共享同一个经验回放池和策略,不同的竞争信息所对应的奖励和动作不同,因此在计算优势函数时,在竞争中处于领先位置的智能体产生的动作具有更大的优势。而在评估阶段,执行只需要智能体的本体状态信息,将竞争性信息所对应的信道做补零处理。
在实际测试环节,研究人员通过MuJoCo中的multi-Ant、multi-HalfCheetah和multi-Walker2d竞争赛跑环境进行验证。结果表明,利用竞争信息的智能体可以获得更好的训练效果。
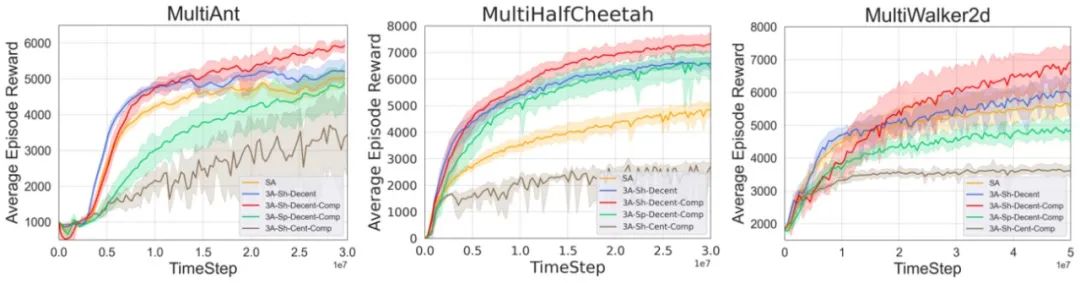
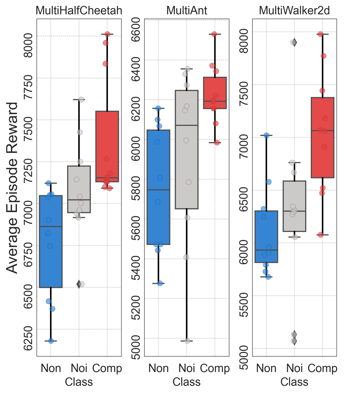
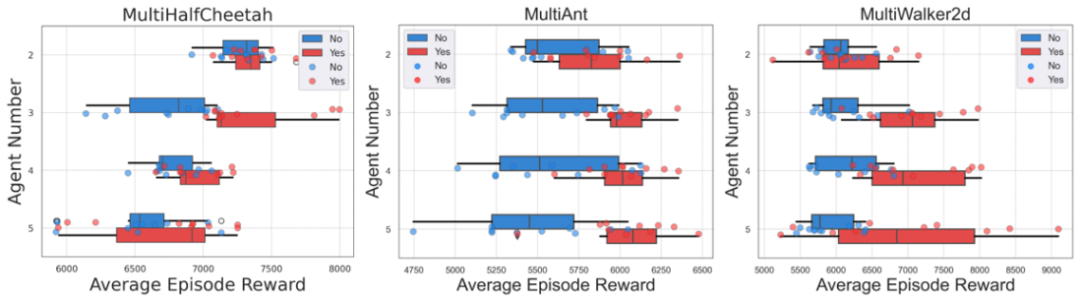
为了进一步验证竞争性信息的有效性,研究人员分别进行了三组对比实验分别为:有竞争信息、无竞争信息及噪声信息。实验结果表明,智能体的确从竞争信息中学到了特征。此外,研究人员还探索了多体竞争环境下智能体数量对竞争效果的影响,观察发现不同类型的智能体在竞争中的潜力不同,适度的竞争者数量能够达到最佳的竞争效果,进而提升智能体成绩。但是当竞争者增加时,会引入过多的竞争信息,导致观察维度增大,使代表竞争的附加信号掩盖智能体的本体信号,造成负面影响。
▍在对抗中发育身体——引导智能体朝更强方向进化
通过形态学和控制的协同优化来训练智能体来适应特定任务做法,已经受到业界广泛关注。然而,在双人对抗竞争场景中,智能体是否存在最优配置和策略仍然是一个具有挑战性的问题。为此研究人员提出了“竞争进化”(CompetEvo)的概念,即在对抗过程中同时进化智能体的形态设计和策略。与传统的固定形态智能体相比,采用竞争进化策略的智能体,能够进化出更适合于战斗的形态设计和策略,从而在战斗场景中获得优势。此外,研究人员还观察到,在不对称形态对抗中,智能体展现出了令人印象深刻的行为。

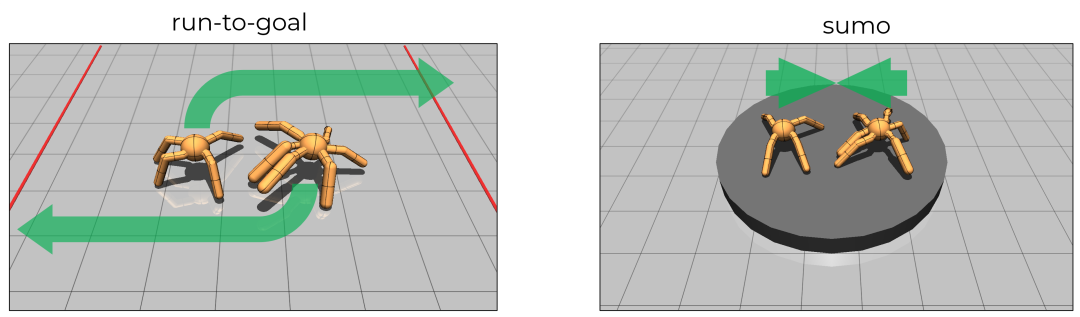
该实验分别在run-to-goal和sumo两个场景中实施。其中Run-to-goal的目标是优先到达对手身后的红线。在实验过程中,两个智能体会相互竞争,一方面试图阻止对方通过自己到达红线,另一方面也会竭力突破对方的防守。而“Sumo”则是一种经典的相扑游戏,其中智能体的任务是努力将对手推出竞技场或者将对手击倒,以此来赢得比赛。
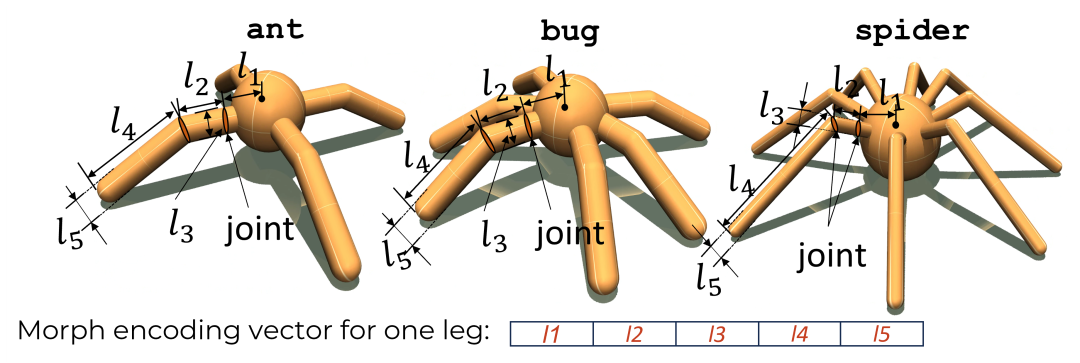
首先,研究人员对智能体的形态参数进行编码,对肢节的长度和粗壮度进行调整,同时对应调节关节输出的扭矩和力的大小。其次,研究人员选取了三种智能体作为基础智能体ant、bug和spider。通过发育形态的调整,得到了这三种智能体的进化版本,分别命名为evo-ant、evo-bug和evo-spider。
对抗协同进化的过程分为形态生成和竞技场对抗两个阶段,研究人员构建分别构建了形态子策略和战术子策略。在每个回合开始时,首先由形态子策略负责生成智能体的形态,随后战术子策略会接管并控制智能体进行对抗。整个对抗协同进化的信息流动如图所示:

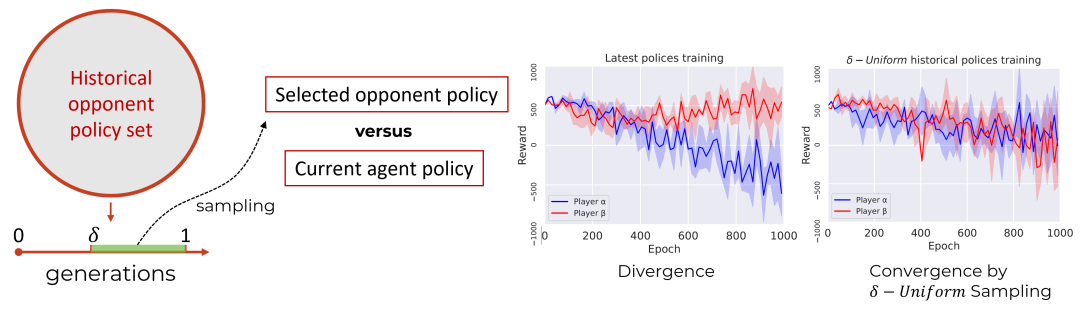
在双人博弈的训练中,避免对抗中出现明显的不平衡是非常关键的。训练中一旦出现不平衡的现象,就有可能发生训练策略的分歧,即处于劣势的智能体在竞争中无法获取有用的信息,而处于优势的智能体在策略上缺乏鲁棒性。为此研究人员使用采样实现双人对抗训练的均衡。每次从对手的历史策略集中按照采样出策略,以确保当前策略能够战胜所有历史上的对手策略。
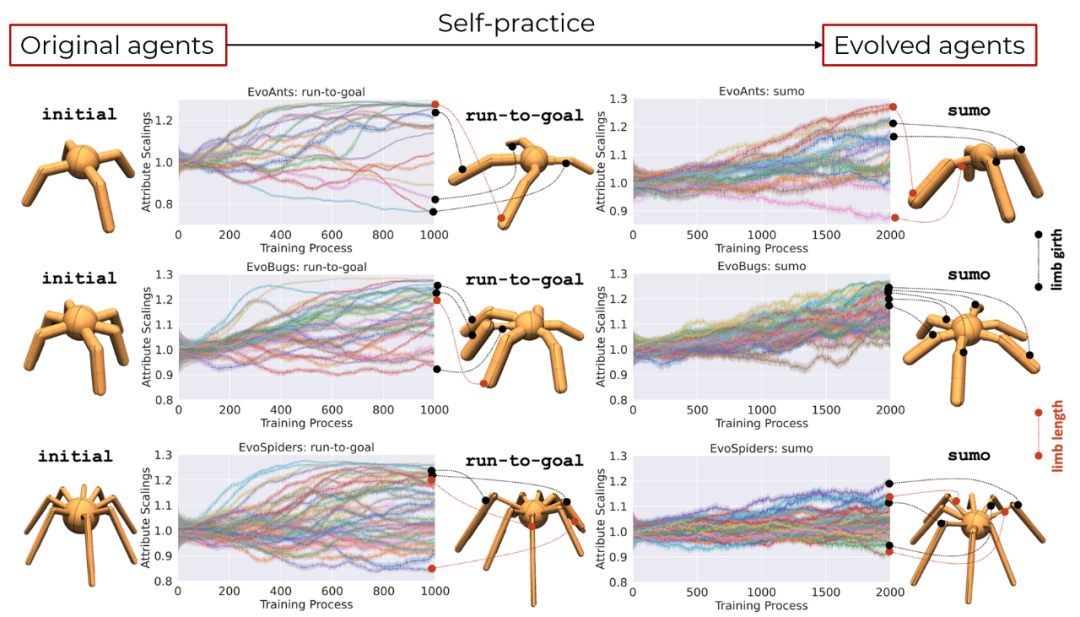
在经历了对抗任务下长期的形态与控制的协同进化后,三种基础智能体的形态参数分别收敛到合适的参数值。在run-to-goal的任务中,研究人员发现智能体更倾向于沿行进方向进化出粗壮的肢节,这有助于他们保持沿行进方向的平衡。而在sumo的任务中,智能体倾向于生长出各个方向上的粗壮肢节,这使智能体在各个方向上都不存在弱点。
研究人员将进化出的智能体和基础版本的智能体放在一起进行对抗测试,结果表明在对抗中发育身体的智能体能够具有更高的胜率。
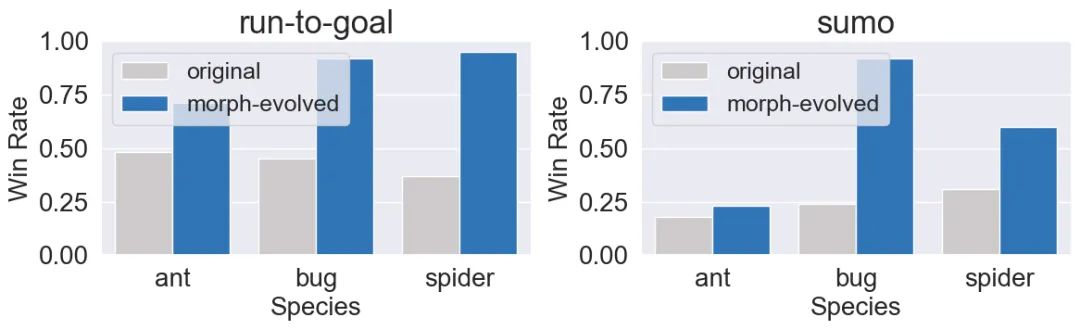
此外,研究人员还将不同种类的智能体做交叉对抗测试,结果同样表明在对抗中协同发育身体的智能体相比其固定形态的版本能够具有更高的胜率。甚至在一些实验中,本身毫无胜算的智能体在经过身体和策略协同进化后,具备了绝对统治性优势。经过大量实验,研究人员观察到一些合理发育和利用身体形态从而对比赛完成绝杀的涌现现象:通过张开肢节扩大防守面积来抵抗冲击,进化出更大的前腿、利用惯性试图将自己向前甩的行为。

进化后的智能体具有绝对优势(sumo场景)

进化后的智能体具有绝对优势(run-to-goal场景)

智能体进化出粗壮的前肢将自己甩出
▍结语与未来:
竞争行为学习与对抗形态学习为机器人在竞争中学习更强的行为和更有利的形态奠定了基础。未来竞争性与对抗性学习的理念将被更广泛地应用于不同领域,如游戏对抗、体育比赛战术、军事战略等,促进人工智能与机器人到跨学科的应用与合作。